
一、 引言
深度学习带来了机器学习的革命。最近非常火的AlphaGo以及比较流行的人脸识别、语音识别、机器翻译、自动驾驶等应用都是借助于深度学习。可以说深度学习已经成为了人工智能中最核心的一项技术。在八九十年代之前,神经网络就已经出现了,不过那个时候受限于计算能力,模型的规模比较小,所以它的表现不如一些经过优化过的其他机器学习方法,这样就很难解决真实的大规模问题。
随着计算能力的增加,可以看到深度学习解决问题的精度,已经超过了其他机器学习方法。以图片识别问题为例,在 2011 年的时候,它的错误率是 26%,而人只有 5%,所以这个时候离实用有非常大的距离。到 2016 年为止,它的错误率已经减少到了 3% 左右,深度学习在该领域呈现出非常惊人的能力,这就是为什么深度学习在图像识别领域吸引了产业界的大量关注。
二、绪论
思维学普遍认为,人类大脑的思维分为抽象(逻辑)思维、形象(直观)思维和灵感(顿悟)思维三种基本方式。人工神经网络就是模拟人思维的第二种方式。这是一个非线性动力学系统,其特色在于信息的分布式存储和并行协同处理。虽然单个神经元的结构极其简单,功能有限,但大量神经元构成的网络系统所能实现的行为却是极其丰富多彩的。
逻辑性的思维是指根据逻辑规则进行推理的过程。它先将信息化成概念,并用符号表示,然后,根据符号运算按串行模式进行逻辑推理。
这一过程可以写成串行的指令,让计算机执行。然而,直观性的思维是将分布式存储的信息综合起来,结果是忽然间产生的想法或解决问题的办法。
这种思维方式的根本之点在于以下两点:1.信息是通过神经元上的兴奋模式分布储在网络上;2.信息处理是通过神经元之间同时相互作用的动态过程来完成的。
三、概念
神经网络是一门重要的机器学习技术。它是目前最为火热的研究方向–深度学习的基础。学习神经网络不仅可以让你掌握一门强大的机器学习方法,同时也可以更好地帮助你理解深度学习技术。
神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。人脑中的神经网络是一个非常复杂的组织。成人的大脑中估计有1000亿个神经元之多。神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。
神经元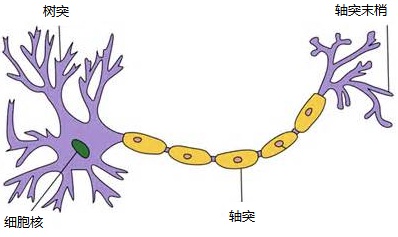
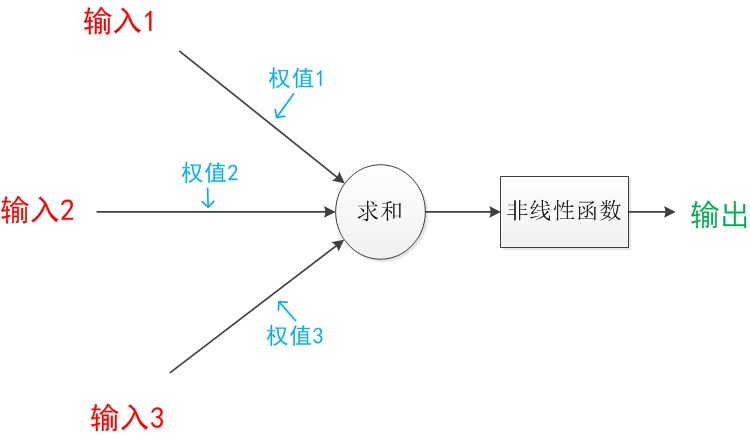
下图是一个典型的神经元模型:包含有3个输入,1个输出,以及2个计算功能。连接是神经元中最重要的东西。每一个连接上都有一个权重。一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。我们使用a来表示输入,用w来表示权值。一个表示连接的有向箭头可以这样理解:在初端,传递的信号大小仍然是a,端中间有加权参数w,经过这个加权后的信号会变成aw,因此在连接的末端,信号的大小就变成了aw。
神经元模型
神经网络分为单层神经网络(感知器)、双层神经网络(多层感知器)、多层神经网络(深度学习)。
四、单层神经网络
拥有一个计算层的神经网络被称作单层神经网络。
1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他给它起了一个名字–“感知器”(Perceptron)(有的文献翻译成“感知机”,下文统一用“感知器”来指代)。
感知器只能做简单的线性分类任务。
单层神经网络模型
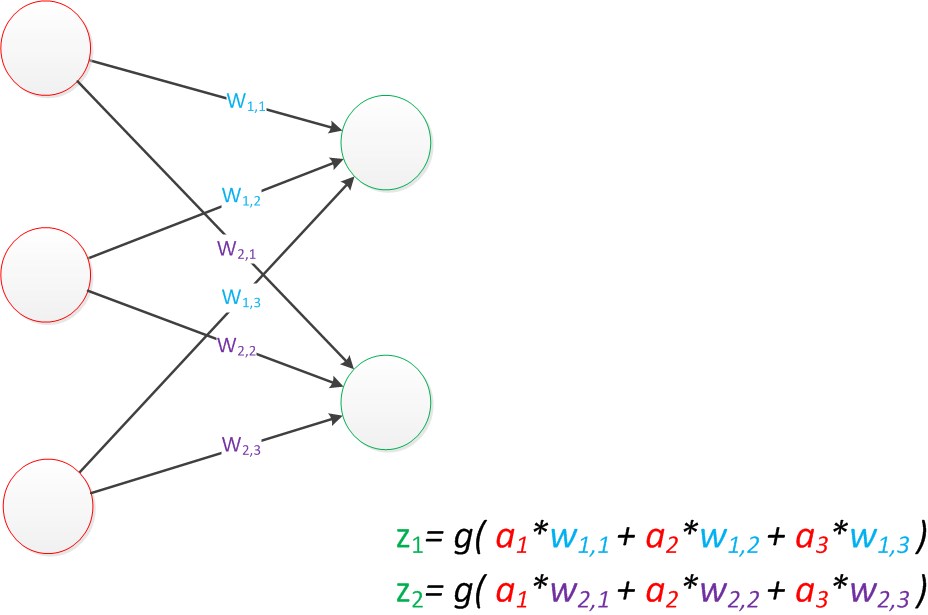
五、两层神经网络
两层神经网络除了拥有一个输入层、输出层以外,还增加了中间层。中间层和输出层都是计算层。
Minsky说过单层神经网络无法解决异或问题。但是当增加一个计算层以后,两层神经网络不仅可以解决异或问题,而且具有非常好的非线性分类效果。不过两层神经网络的计算是一个问题,没有一个较好的解法。
1986年,Rumelhar和Hinton等人提出了反向传播(Backpropagation,BP)算法,解决了两层神经网络所需要的复杂计算量问题,从而带动了业界使用两层神经网络研究的热潮。目前,大量的教授神经网络的教材,都是重点介绍两层(带一个隐藏层)神经网络的内容。
两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个中间层。此时,中间层和输出层都是计算层。我们扩展上节的单层神经网络,在右边新加一个层次(只含有一个节点)。
双层神经网络模型
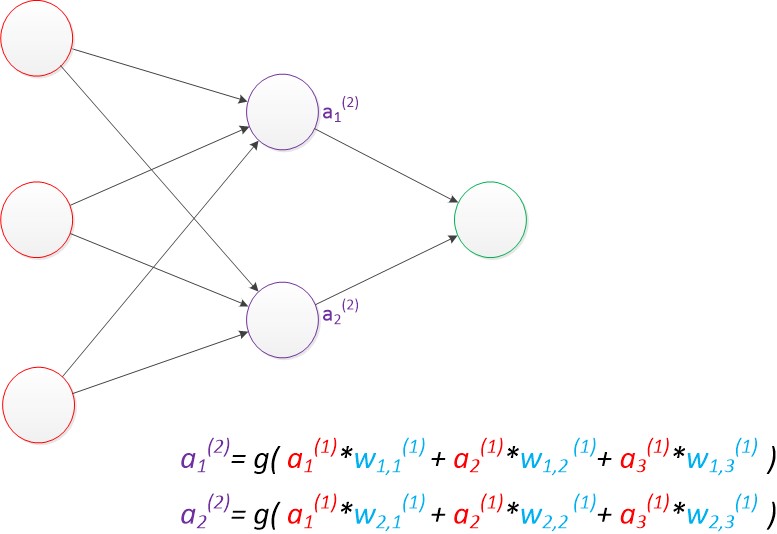
与单层神经网络不同。理论证明,两层神经网络可以无限逼近任意连续函数。
但是神经网络仍然存在若干的问题:尽管使用了BP算法,一次神经网络的训练仍然耗时太久,而且困扰训练优化的一个问题就是局部最优解问题,这使得神经网络的优化较为困难。同时,隐藏层的节点数需要调参,这使得使用不太方便,工程和研究人员对此多有抱怨。
六、多层神经网络(深度学习)
2006年,Hinton在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。与传统的训练方式不同,“深度信念网络”有一个“预训练”(pre-training)的过程,这可以方便的让神经网络中的权值找到一个接近最优解的值,之后再使用“微调”(fine-tuning)技术来对整个网络进行优化训练。这两个技术的运用大幅度减少了训练多层神经网络的时间。他给多层神经网络相关的学习方法赋予了一个新名词–“深度学习”。
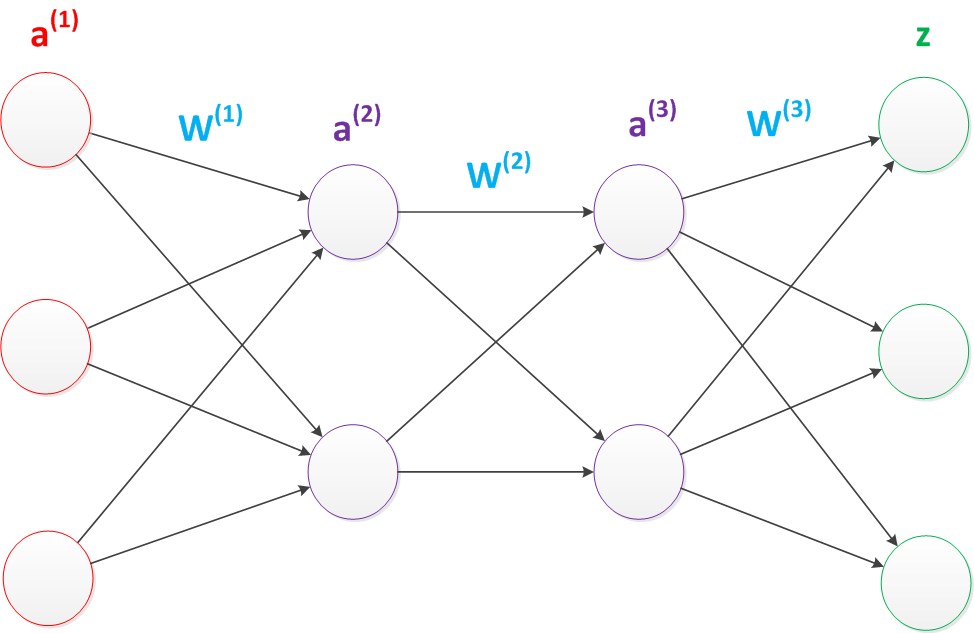
与两层层神经网络不同。多层神经网络中的层数增加了很多。增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
多层神经网络模型
目前,深度神经网络在人工智能界占据统治地位。但凡有关人工智能的产业报道,必然离不开深度学习。神经网络界当下的四位引领者除了前文所说的Ng,Hinton以外,还有CNN的发明人Yann Lecun,以及《Deep Learning》的作者Bengio。
前段时间一直对人工智能持谨慎态度的马斯克,搞了一个OpenAI项目,邀请Bengio作为高级顾问。马斯克认为,人工智能技术不应该掌握在大公司如Google,Facebook的手里,更应该作为一种开放技术,让所有人都可以参与研究。马斯克的这种精神值得让人敬佩。
多层神经网络的研究仍在进行中。现在最为火热的研究技术包括RNN,LSTM等,研究方向则是图像理解方面。图像理解技术是给计算机一幅图片,让它用语言来表达这幅图片的意思。ImageNet竞赛也在不断召开,有更多的方法涌现出来,刷新以往的正确率。
七、 总结
神经网络的发展历史曲折荡漾,既有被人捧上天的时刻,也有摔落在街头无人问津的时段,中间经历了数次大起大落。从单层神经网络(感知器)开始,到包含一个隐藏层的两层神经网络,再到多层的深度神经网络,一共有三次兴起过程。
如果把1949年Hebb模型提出到1958年的感知机诞生这个10年视为落下(没有兴起)的话,那么神经网络算是经历了“三起三落”这样一个过程,跟“小平”同志类似。俗话说,天将降大任于斯人也,必先苦其心志,劳其筋骨。经历过如此多波折的神经网络能够在现阶段取得成功也可以被看做是磨砺的积累吧。
历史最大的好处是可以给现在做参考。科学的研究呈现螺旋形上升的过程,不可能一帆风顺。同时,这也给现在过分热衷深度学习与人工智能的人敲响警钟,因为这不是第一次人们因为神经网络而疯狂了。1958年到1969年,以及1985年到1995,这两个十年间人们对于神经网络以及人工智能的期待并不现在低,可结果如何大家也能看的很清楚。
因此,冷静才是对待目前深度学习热潮的最好办法。如果因为深度学习火热,或者可以有“钱景”就一窝蜂的涌入,那么最终的受害人只能是自己。神经网络界已经两次有被人们捧上天了的境况,相信也对于捧得越高,摔得越惨这句话深有体会。因此,神经网络界的学者也必须给这股热潮浇上一盆水,不要让媒体以及投资家们过分的高看这门技术。很有可能,三十年河东,三十年河西,在几年后,神经网络就再次陷入谷底。根据上图的历史曲线图,这是很有可能的。
八、展望
根据一些最近的研究发现,人脑内部进行的计算可能是类似于量子计算形态的东西。而且目前已知的最大神经网络跟人脑的神经元数量相比,仍然显得非常小,仅不及1%左右。所以未来真正想实现人脑神经网络的模拟,可能需要借助量子计算的强大计算能力。
参考
- https://www.cnblogs.com/subconscious/p/5058741.html#eighth
- https://blog.csdn.net/jILRvRTrc/article/details/80578131
- https://baike.baidu.com/item/神经网络算法/1252235?fr=aladdin